Neural Ordinary Differential Equations
A neural ODE is an ODE where a neural network defines its derivative function. For example, with the multilayer perceptron neural network Lux.Chain(Lux.Dense(2, 50, tanh), Lux.Dense(50, 2)), we can define a differential equation which is u' = NN(u). This is done simply by the NeuralODE struct. Let's take a look at an example.
Copy-Pasteable Code
Before getting to the explanation, here's some code to start with. We will follow a full explanation of the definition and training process:
using ComponentArrays, Lux, DiffEqFlux, OrdinaryDiffEq, Optimization, OptimizationOptimJL,
OptimizationOptimisers, Random, Plots
rng = Xoshiro(0)
u0 = Float32[2.0; 0.0]
datasize = 30
tspan = (0.0f0, 1.5f0)
tsteps = range(tspan[1], tspan[2]; length = datasize)
function trueODEfunc!(du, u, p, t)
true_A = [-0.1 2.0; -2.0 -0.1]
du .= ((u .^ 3)'true_A)'
end
prob_trueode = ODEProblem(trueODEfunc!, u0, tspan)
ode_data = Array(solve(prob_trueode, Tsit5(); saveat = tsteps))
dudt2 = Chain(x -> x .^ 3, Dense(2, 50, tanh), Dense(50, 2))
p, st = Lux.setup(rng, dudt2)
prob_neuralode = NeuralODE(dudt2, tspan, Tsit5(); saveat = tsteps)
function predict_neuralode(p)
Array(prob_neuralode(u0, p, st)[1])
end
function loss_neuralode(p)
pred = predict_neuralode(p)
loss = sum(abs2, ode_data .- pred)
return loss
end
# Do not plot by default for the documentation
# Users should change doplot=true to see the plots callbacks
function callback(state, l; doplot = false)
println(l)
# plot current prediction against data
if doplot
pred = predict_neuralode(state.u)
plt = scatter(tsteps, ode_data[1, :]; label = "data")
scatter!(plt, tsteps, pred[1, :]; label = "prediction")
display(plot(plt))
end
return false
end
pinit = ComponentArray(p)
callback((; u = pinit), loss_neuralode(pinit); doplot = true)
# use Optimization.jl to solve the problem
adtype = Optimization.AutoZygote()
optf = Optimization.OptimizationFunction((x, p) -> loss_neuralode(x), adtype)
optprob = Optimization.OptimizationProblem(optf, pinit)
result_neuralode = Optimization.solve(
optprob, OptimizationOptimisers.Adam(0.05); callback = callback, maxiters = 300)
optprob2 = remake(optprob; u0 = result_neuralode.u)
result_neuralode2 = Optimization.solve(
optprob2, Optim.BFGS(; initial_stepnorm = 0.01); callback, allow_f_increases = false)
callback((; u = result_neuralode2.u), loss_neuralode(result_neuralode2.u); doplot = true)false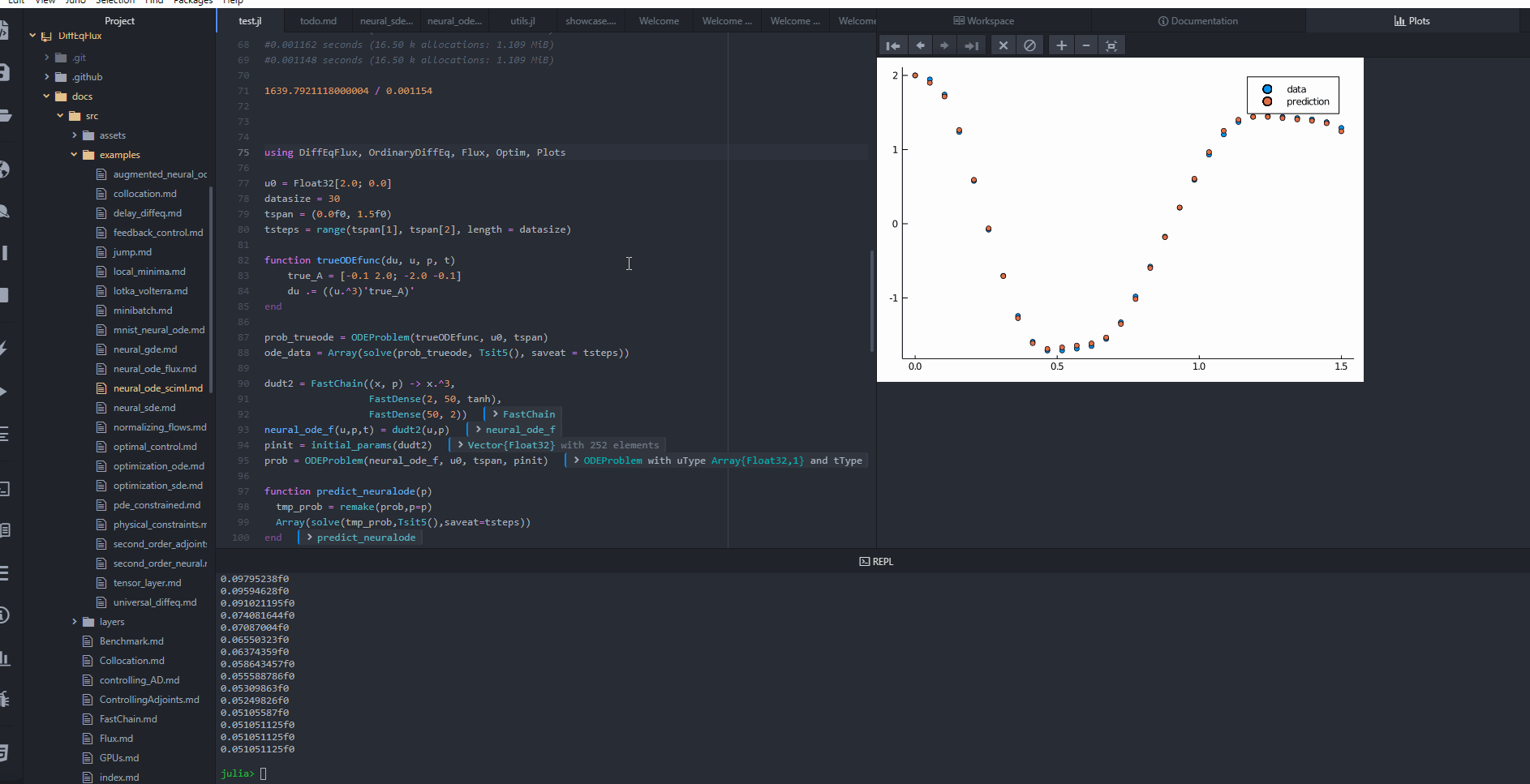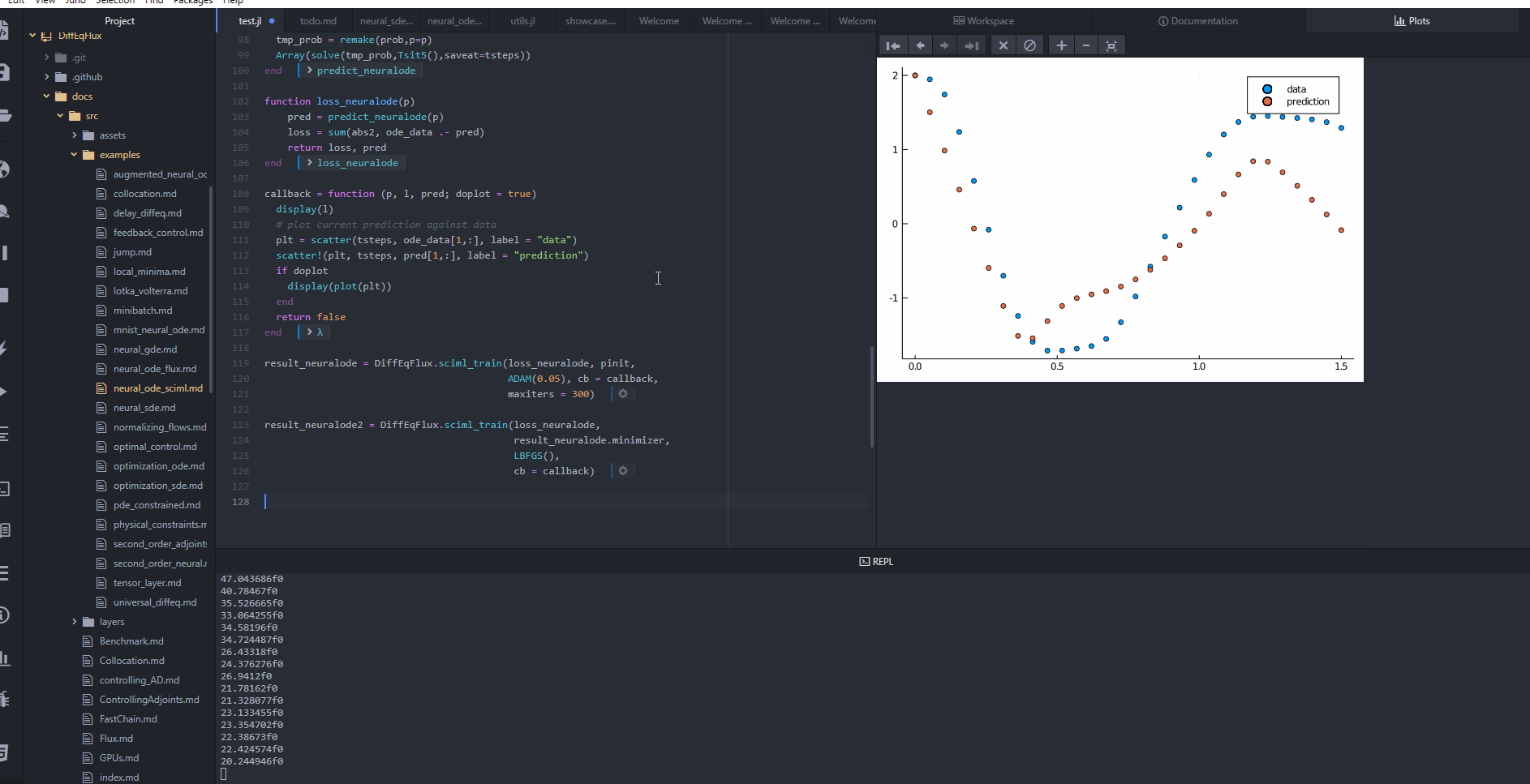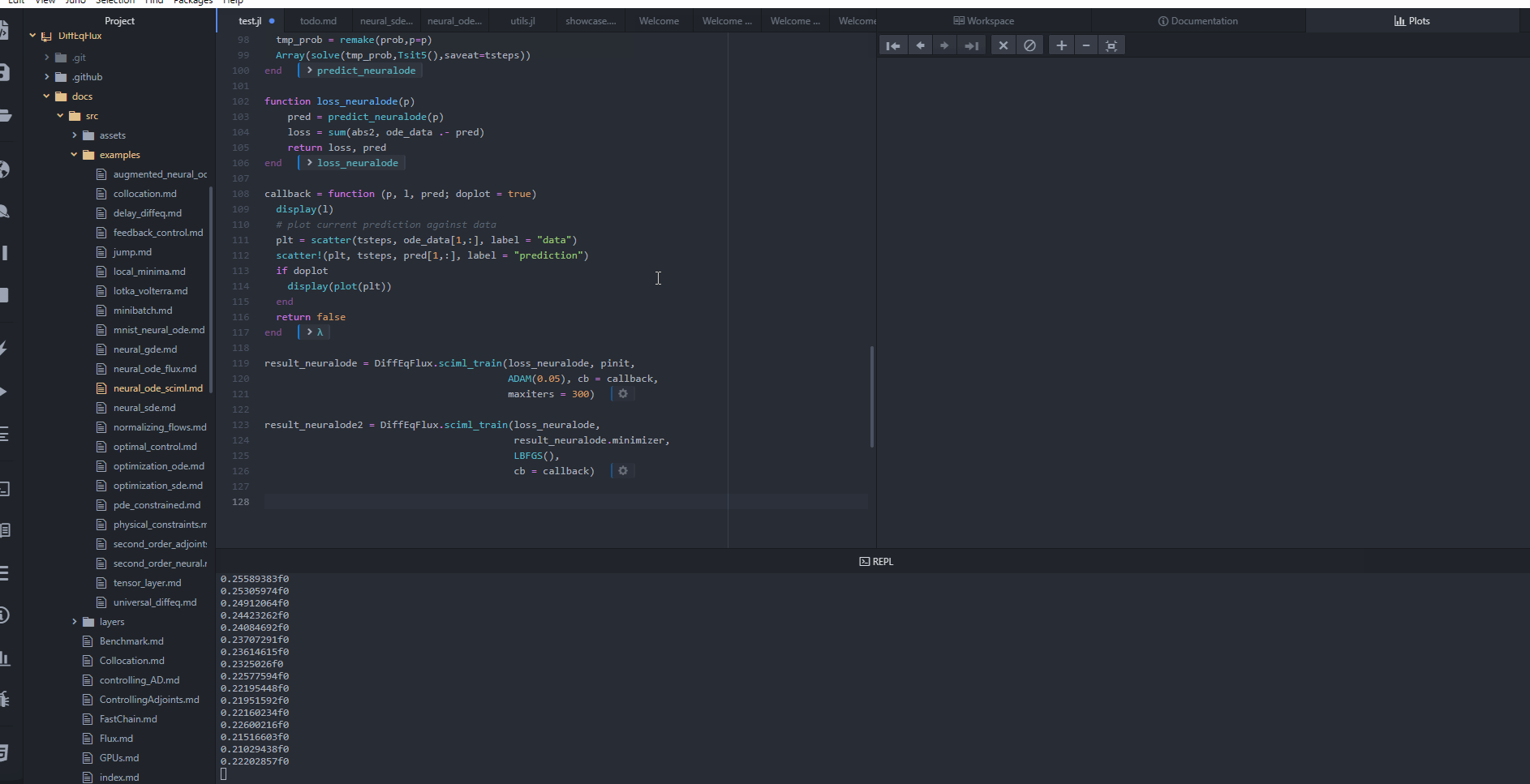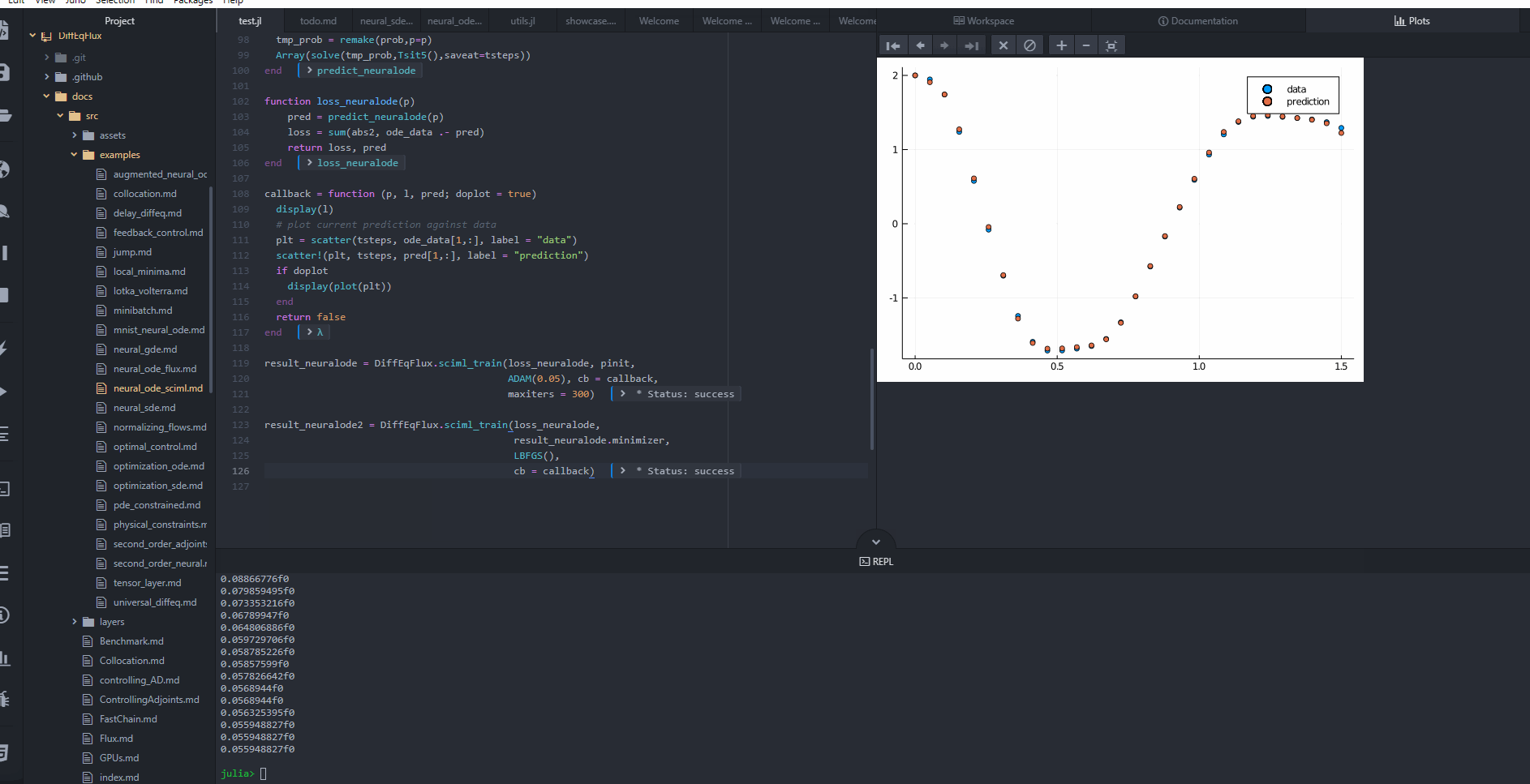
Explanation
Let's get a time series array from a spiral ODE to train against.
using ComponentArrays, Lux, DiffEqFlux, OrdinaryDiffEq, Optimization, OptimizationOptimJL,
OptimizationOptimisers, Random, Plots
rng = Xoshiro(0)
u0 = Float32[2.0; 0.0]
datasize = 30
tspan = (0.0f0, 1.5f0)
tsteps = range(tspan[1], tspan[2]; length = datasize)
function trueODEfunc!(du, u, p, t)
true_A = [-0.1 2.0; -2.0 -0.1]
du .= ((u .^ 3)'true_A)'
end
prob_trueode = ODEProblem(trueODEfunc!, u0, tspan)
ode_data = Array(solve(prob_trueode, Tsit5(); saveat = tsteps))2×30 Matrix{Float32}:
2.0 1.9465 1.74178 1.23837 0.577126 … 1.40687 1.37022 1.29214
0.0 0.798832 1.46473 1.80877 1.86465 0.451368 0.728685 0.972085Now let's define a neural network with a NeuralODE layer. First, we define the layer. Here we're going to use Lux.Chain, which is a suitable neural network structure for NeuralODEs with separate handling of state variables:
dudt2 = Chain(x -> x .^ 3, Dense(2, 50, tanh), Dense(50, 2))
p, st = Lux.setup(rng, dudt2)
prob_neuralode = NeuralODE(dudt2, tspan, Tsit5(); saveat = tsteps)NeuralODE(
model = Chain(
layer_1 = WrappedFunction(#2),
layer_2 = Dense(2 => 50, tanh), # 150 parameters
layer_3 = Dense(50 => 2), # 102 parameters
),
) # Total: 252 parameters,
# plus 0 states.Note that we can directly use Chains from Lux.jl as well, for example:
dudt2 = Chain(x -> x .^ 3, Dense(2, 50, tanh), Dense(50, 2))In our model, we used the x -> x.^3 assumption in the model. By incorporating structure into our equations, we can reduce the required size and training time for the neural network, but a good guess needs to be known!
From here we build a loss function around it. The NeuralODE has an optional second argument for new parameters, which we will use to change the neural network iteratively in our training loop. We will use the L2 loss of the network's output against the time series data:
function predict_neuralode(p)
Array(prob_neuralode(u0, p, st)[1])
end
function loss_neuralode(p)
pred = predict_neuralode(p)
loss = sum(abs2, ode_data .- pred)
return loss
endloss_neuralode (generic function with 1 method)We define a callback function. In this example, we set doplot=false because otherwise it would show every step and overflow the documentation, but for your use case set doplot=true to see a live animation of the training process!
# Callback function to observe training
callback = function (state, l; doplot = false)
println(l)
# plot current prediction against data
if doplot
pred = predict_neuralode(state.u)
plt = scatter(tsteps, ode_data[1, :]; label = "data")
scatter!(plt, tsteps, pred[1, :]; label = "prediction")
display(plot(plt))
end
return false
end
pinit = ComponentArray(p)
callback((; u = pinit), loss_neuralode(pinit))falseWe then train the neural network to learn the ODE.
Here we showcase starting the optimization with Adam to more quickly find a minimum, and then honing in on the minimum by using LBFGS. By using the two together, we can fit the neural ODE in 9 seconds! (Note, the timing commented out the plotting). You can easily incorporate the procedure below to set up custom optimization problems. For more information on the usage of Optimization.jl, please consult this documentation.
The x and p variables in the optimization function are different from x and p above. The optimization function runs over the space of parameters of the original problem, so x_optimization == p_original.
# Train using the Adam optimizer
adtype = Optimization.AutoZygote()
optf = Optimization.OptimizationFunction((x, p) -> loss_neuralode(x), adtype)
optprob = Optimization.OptimizationProblem(optf, pinit)
result_neuralode = Optimization.solve(
optprob, OptimizationOptimisers.Adam(0.05); callback = callback, maxiters = 300)retcode: Default
u: ComponentVector{Float32}(layer_1 = Float32[], layer_2 = (weight = Float32[-2.0201523 1.5047237; -0.48799333 -0.22094278; … ; -0.20681679 0.01847002; 0.5569128 -0.8740125], bias = Float32[-0.62723947, -0.81310475, -0.51000154, 1.3997053, -0.38143492, 0.816305, 0.8593733, -0.0018838106, 0.91819584, 0.7497174 … 0.25200874, -0.9336435, -1.5443151, 0.5430574, -0.84973997, 0.7290552, -0.08725739, 0.6089473, 0.2810185, 0.40009674]), layer_3 = (weight = Float32[-0.2583687 0.7560768 … -0.08102027 0.6142381; -0.036943514 -0.06070116 … -0.11565053 -0.03477804], bias = Float32[-0.7600118, 0.18344054]))We then complete the training using a different optimizer, starting from where Adam stopped. We do allow_f_increases=false to make the optimization automatically halt when near the minimum.
# Retrain using the LBFGS optimizer
optprob2 = remake(optprob; u0 = result_neuralode.u)
result_neuralode2 = Optimization.solve(optprob2, Optim.BFGS(; initial_stepnorm = 0.01);
callback = callback, allow_f_increases = false)retcode: Failure
u: ComponentVector{Float32}(layer_1 = Float32[], layer_2 = (weight = Float32[-2.0126545 1.514201; -0.4537616 -0.2714983; … ; -0.20207554 0.0049754987; 0.5118748 -0.8989092], bias = Float32[-0.62880117, -0.82263345, -0.51824933, 1.4233034, -0.4083882, 0.8540141, 0.9064511, -0.007135968, 0.96603423, 0.74887615 … 0.2775293, -0.9620893, -1.5993142, 0.54372436, -0.89504546, 0.7264805, -0.06539868, 0.6021529, 0.28532684, 0.42403194]), layer_3 = (weight = Float32[-0.2555572 0.7702589 … -0.08715843 0.64729977; 0.0066560083 -0.04331797 … -0.19405241 -0.037947312], bias = Float32[-0.7268071, 0.36283565]))And then we use the callback with doplot=true to see the final plot:
callback((; u = result_neuralode2.u), loss_neuralode(result_neuralode2.u); doplot = true)