GPU-Accelerated Physics-Informed Neural Network (PINN) PDE Solvers
Machine learning is all the rage. Everybody thinks physics is cool.
Therefore, using machine learning to solve physics equations? 🧠💥
So let's be cool and use a physics-informed neural network (PINN) to solve the Heat Equation. Let's be even cooler by using GPUs (ironically, creating even more heat, but it's the heat equation so that's cool).
Step 1: Import Libraries
To solve PDEs using neural networks, we will use the NeuralPDE.jl package. This package uses ModelingToolkit's symbolic PDESystem as an input, and it generates an Optimization.jlOptimizationProblem which, when solved, gives the weights of the neural network that solve the PDE. In the end, our neural network NN satisfies the PDE equations and is thus the solution to the PDE! Thus our packages look like:
# High Level Interface
import NeuralPDE
import ModelingToolkit as MTK
using ModelingToolkit: @parameters, @variables, Differential, PDESystem
using DomainSets: Interval
# Optimization Libraries
import Optimization as OPT
import OptimizationOptimisers
# Machine Learning Libraries and Helpers
import Lux
import LuxCUDA
import ComponentArrays
import MLDataDevices
const gpud = MLDataDevices.gpu_device() # allocate a GPU device
# Standard Libraries
import Printf
import Random
# Plotting
import PlotsProblem Setup
Let's solve the 2+1-dimensional Heat Equation. This is the PDE:
\[∂_t u(x, y, t) = ∂^2_x u(x, y, t) + ∂^2_y u(x, y, t) \, ,\]
with the initial and boundary conditions:
\[\begin{align*} u(x, y, 0) &= e^{x+y} \cos(x + y) \, ,\\ u(0, y, t) &= e^{y} \cos(y + 4t) \, ,\\ u(2, y, t) &= e^{2+y} \cos(2 + y + 4t) \, ,\\ u(x, 0, t) &= e^{x} \cos(x + 4t) \, ,\\ u(x, 2, t) &= e^{x+2} \cos(x + 2 + 4t) \, , \end{align*}\]
on the space and time domain:
\[x \in [0, 2] \, ,\ y \in [0, 2] \, , \ t \in [0, 2] \, ,\]
with physics-informed neural networks.
Step 2: Define the PDESystem
First, let's use ModelingToolkit's PDESystem to represent the PDE. To do this, basically just copy-paste the PDE definition into Julia code. This looks like:
@parameters t x y
@variables u(..)
Dxx = Differential(x)^2
Dyy = Differential(y)^2
Dt = Differential(t)
t_min = 0.0
t_max = 2.0
x_min = 0.0
x_max = 2.0
y_min = 0.0
y_max = 2.0
# 2D PDE
eq = Dt(u(t, x, y)) ~ Dxx(u(t, x, y)) + Dyy(u(t, x, y))
analytic_sol_func(t, x, y) = exp(x + y) * cos(x + y + 4t)
# Initial and boundary conditions
bcs = [u(t_min, x, y) ~ analytic_sol_func(t_min, x, y),
u(t, x_min, y) ~ analytic_sol_func(t, x_min, y),
u(t, x_max, y) ~ analytic_sol_func(t, x_max, y),
u(t, x, y_min) ~ analytic_sol_func(t, x, y_min),
u(t, x, y_max) ~ analytic_sol_func(t, x, y_max)]
# Space and time domains
domains = [t ∈ Interval(t_min, t_max),
x ∈ Interval(x_min, x_max),
y ∈ Interval(y_min, y_max)]
MTK.@named pde_system = PDESystem(eq, bcs, domains, [t, x, y], [u(t, x, y)])\[ \begin{align} \frac{\mathrm{d}}{\mathrm{d}t} ~ u\left( t, x, y \right) &= \frac{\mathrm{d}^{2}}{\mathrm{d}y^{2}} ~ u\left( t, x, y \right) + \frac{\mathrm{d}^{2}}{\mathrm{d}x^{2}} ~ u\left( t, x, y \right) \end{align} \]
We used the wildcard form of the variable definition @variables u(..) which then requires that we always specify what the dependent variables of u are. This is because in the boundary conditions we change from using u(t,x,y) to more specific points and lines, like u(t,x_max,y).
Step 3: Define the Lux Neural Network
Now let's define the neural network that will act as our solution. We will use a simple multi-layer perceptron, like:
inner = 25
chain = Lux.Chain(Lux.Dense(3, inner, Lux.σ),
Lux.Dense(inner, inner, Lux.σ),
Lux.Dense(inner, inner, Lux.σ),
Lux.Dense(inner, inner, Lux.σ),
Lux.Dense(inner, 1))
ps = Lux.setup(Random.default_rng(), chain)[1](layer_1 = (weight = Float32[-0.5535742 0.2818954 0.7413074; 0.4751941 0.06418073 0.82065403; … ; -0.886961 0.7859945 0.60123706; 0.14313006 0.29417646 -0.2912377], bias = Float32[0.066314414, -0.32871017, 0.16304696, -0.06695745, -0.008654533, 0.15897869, 0.012715995, -0.2058671, 0.20000392, -0.00073588244 … 0.45843202, -0.2698565, 0.4059029, 0.11745618, 0.22176118, -0.4832909, 0.10823129, 0.16932894, -0.38620758, 0.24772519]), layer_2 = (weight = Float32[0.16369733 -0.34306738 … -0.14422122 -0.1544843; -0.21156202 -0.2909667 … 0.022742525 0.2807432; … ; 0.3434233 0.32313117 … -0.018927168 -0.21227531; -0.1762888 0.29772133 … -0.21693747 -0.30371007], bias = Float32[0.13215609, 0.031723928, 0.035815, -0.004002905, -0.026951313, -0.0676858, -0.19569, 0.11064398, -0.017607594, -0.10461779 … 0.184378, -0.034622192, -0.05633278, -0.06719544, 0.19759576, -0.0836015, -0.09874282, -0.19192502, 0.02807114, 0.15909469]), layer_3 = (weight = Float32[-0.17620221 -0.29560098 … -0.16673782 -0.0224478; -0.06542692 0.12213459 … -0.2373269 -0.16350514; … ; 0.098808855 0.3389087 … -0.05059716 -0.32232788; -0.15730737 0.18519823 … 0.19171715 0.028192017], bias = Float32[0.005939412, -0.042444944, 0.104392454, -0.058843873, -0.13536072, 0.046051573, -0.09828639, -0.15098497, -0.1472358, -0.06898916 … -0.17956047, -0.077257894, -0.018815804, 0.024032425, 0.11391854, 0.051411558, -0.13495705, -0.18758819, 0.04030044, 0.009285283]), layer_4 = (weight = Float32[0.29861894 -0.26658455 … 0.25955483 -0.12238257; 0.22801766 0.04764318 … 0.113921784 -0.27174056; … ; 0.06563947 -0.10233729 … 0.24972624 0.22216848; 0.024736634 0.04983555 … -0.16247469 0.2006261], bias = Float32[-0.10133612, 0.11978881, 0.041668773, 0.11940162, -0.08117767, -0.020776033, 0.13517001, 0.114560746, -0.12553866, 0.112335846 … -0.10811863, 0.07963872, -0.19800799, 0.021682214, 0.086531304, 0.021163559, 0.18548922, 0.05204437, -0.08581402, 0.16169448]), layer_5 = (weight = Float32[-0.31101325 0.10640418 … -0.31699818 0.17244074], bias = Float32[0.09212842]))Step 4: Place it on the GPU.
Just plop it on that sucker. We must ensure that our initial parameters for the neural network are on the GPU. If that is done, then the internal computations will all take place on the GPU. This is done by using the gpud function (i.e. the GPU device we created at the start) on the initial parameters, like:
ps = ps |> ComponentArrays.ComponentArray |> gpud .|> Float64ComponentArrays.ComponentVector{Float64, CUDA.CuArray{Float64, 1, CUDA.DeviceMemory}, Tuple{ComponentArrays.Axis{(layer_1 = ViewAxis(1:100, Axis(weight = ViewAxis(1:75, ShapedAxis((25, 3))), bias = ViewAxis(76:100, Shaped1DAxis((25,))))), layer_2 = ViewAxis(101:750, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_3 = ViewAxis(751:1400, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_4 = ViewAxis(1401:2050, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_5 = ViewAxis(2051:2076, Axis(weight = ViewAxis(1:25, ShapedAxis((1, 25))), bias = ViewAxis(26:26, Shaped1DAxis((1,))))))}}}(layer_1 = (weight = [-0.5535742044448853 0.28189539909362793 0.7413073778152466; 0.4751940965652466 0.06418073177337646 0.820654034614563; … ; -0.8869609832763672 0.7859945297241211 0.6012370586395264; 0.14313006401062012 0.29417645931243896 -0.2912377119064331], bias = [0.06631441414356232, -0.3287101686000824, 0.1630469560623169, -0.06695745140314102, -0.008654532954096794, 0.1589786857366562, 0.01271599531173706, -0.20586709678173065, 0.20000392198562622, -0.0007358824368566275 … 0.45843201875686646, -0.2698565125465393, 0.4059028923511505, 0.11745618283748627, 0.22176118195056915, -0.4832909107208252, 0.10823129117488861, 0.1693289428949356, -0.38620758056640625, 0.24772518873214722]), layer_2 = (weight = [0.16369733214378357 -0.34306737780570984 … -0.1442212164402008 -0.15448430180549622; -0.21156202256679535 -0.2909666895866394 … 0.02274252474308014 0.28074321150779724; … ; 0.3434233069419861 0.32313117384910583 … -0.01892716810107231 -0.21227531135082245; -0.17628879845142365 0.29772132635116577 … -0.21693746745586395 -0.30371007323265076], bias = [0.13215608894824982, 0.031723927706480026, 0.03581500053405762, -0.004002904985100031, -0.026951313018798828, -0.0676857978105545, -0.19569000601768494, 0.11064398288726807, -0.017607593908905983, -0.10461778938770294 … 0.1843779981136322, -0.0346221923828125, -0.056332778185606, -0.06719543784856796, 0.1975957602262497, -0.08360149711370468, -0.09874282032251358, -0.1919250190258026, 0.028071140870451927, 0.1590946912765503]), layer_3 = (weight = [-0.1762022078037262 -0.2956009805202484 … -0.16673782467842102 -0.022447800263762474; -0.06542692333459854 0.12213458865880966 … -0.23732690513134003 -0.16350513696670532; … ; 0.09880885481834412 0.33890870213508606 … -0.050597161054611206 -0.3223278820514679; -0.15730737149715424 0.18519823253154755 … 0.19171714782714844 0.02819201722741127], bias = [0.00593941193073988, -0.04244494438171387, 0.10439245402812958, -0.05884387344121933, -0.1353607177734375, 0.046051573008298874, -0.09828639030456543, -0.1509849727153778, -0.14723579585552216, -0.06898915767669678 … -0.17956046760082245, -0.07725789397954941, -0.01881580427289009, 0.02403242513537407, 0.11391854286193848, 0.05141155794262886, -0.13495704531669617, -0.1875881850719452, 0.04030044004321098, 0.009285283274948597]), layer_4 = (weight = [0.29861894249916077 -0.2665845453739166 … 0.25955483317375183 -0.12238256633281708; 0.228017657995224 0.047643180936574936 … 0.11392178386449814 -0.27174055576324463; … ; 0.06563947349786758 -0.1023372933268547 … 0.24972623586654663 0.2221684753894806; 0.024736633524298668 0.04983555153012276 … -0.16247469186782837 0.20062610507011414], bias = [-0.10133612155914307, 0.11978881061077118, 0.04166877269744873, 0.11940161883831024, -0.08117766678333282, -0.020776033401489258, 0.13517001271247864, 0.11456074565649033, -0.1255386620759964, 0.11233584582805634 … -0.10811863094568253, 0.07963871955871582, -0.1980079859495163, 0.021682213991880417, 0.08653130382299423, 0.021163558587431908, 0.185489222407341, 0.05204436928033829, -0.08581402152776718, 0.1616944819688797]), layer_5 = (weight = [-0.31101325154304504 0.10640417784452438 … -0.3169981837272644 0.17244073748588562], bias = [0.09212841838598251]))Step 5: Discretize the PDE via a PINN Training Strategy
strategy = NeuralPDE.GridTraining(0.1)
discretization = NeuralPDE.PhysicsInformedNN(chain,
strategy,
init_params = ps)
prob = NeuralPDE.discretize(pde_system, discretization)OptimizationProblem. In-place: true
u0: ComponentArrays.ComponentVector{Float64, CUDA.CuArray{Float64, 1, CUDA.DeviceMemory}, Tuple{ComponentArrays.Axis{(layer_1 = ViewAxis(1:100, Axis(weight = ViewAxis(1:75, ShapedAxis((25, 3))), bias = ViewAxis(76:100, Shaped1DAxis((25,))))), layer_2 = ViewAxis(101:750, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_3 = ViewAxis(751:1400, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_4 = ViewAxis(1401:2050, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_5 = ViewAxis(2051:2076, Axis(weight = ViewAxis(1:25, ShapedAxis((1, 25))), bias = ViewAxis(26:26, Shaped1DAxis((1,))))))}}}(layer_1 = (weight = [-0.5535742044448853 0.28189539909362793 0.7413073778152466; 0.4751940965652466 0.06418073177337646 0.820654034614563; … ; -0.8869609832763672 0.7859945297241211 0.6012370586395264; 0.14313006401062012 0.29417645931243896 -0.2912377119064331], bias = [0.06631441414356232, -0.3287101686000824, 0.1630469560623169, -0.06695745140314102, -0.008654532954096794, 0.1589786857366562, 0.01271599531173706, -0.20586709678173065, 0.20000392198562622, -0.0007358824368566275 … 0.45843201875686646, -0.2698565125465393, 0.4059028923511505, 0.11745618283748627, 0.22176118195056915, -0.4832909107208252, 0.10823129117488861, 0.1693289428949356, -0.38620758056640625, 0.24772518873214722]), layer_2 = (weight = [0.16369733214378357 -0.34306737780570984 … -0.1442212164402008 -0.15448430180549622; -0.21156202256679535 -0.2909666895866394 … 0.02274252474308014 0.28074321150779724; … ; 0.3434233069419861 0.32313117384910583 … -0.01892716810107231 -0.21227531135082245; -0.17628879845142365 0.29772132635116577 … -0.21693746745586395 -0.30371007323265076], bias = [0.13215608894824982, 0.031723927706480026, 0.03581500053405762, -0.004002904985100031, -0.026951313018798828, -0.0676857978105545, -0.19569000601768494, 0.11064398288726807, -0.017607593908905983, -0.10461778938770294 … 0.1843779981136322, -0.0346221923828125, -0.056332778185606, -0.06719543784856796, 0.1975957602262497, -0.08360149711370468, -0.09874282032251358, -0.1919250190258026, 0.028071140870451927, 0.1590946912765503]), layer_3 = (weight = [-0.1762022078037262 -0.2956009805202484 … -0.16673782467842102 -0.022447800263762474; -0.06542692333459854 0.12213458865880966 … -0.23732690513134003 -0.16350513696670532; … ; 0.09880885481834412 0.33890870213508606 … -0.050597161054611206 -0.3223278820514679; -0.15730737149715424 0.18519823253154755 … 0.19171714782714844 0.02819201722741127], bias = [0.00593941193073988, -0.04244494438171387, 0.10439245402812958, -0.05884387344121933, -0.1353607177734375, 0.046051573008298874, -0.09828639030456543, -0.1509849727153778, -0.14723579585552216, -0.06898915767669678 … -0.17956046760082245, -0.07725789397954941, -0.01881580427289009, 0.02403242513537407, 0.11391854286193848, 0.05141155794262886, -0.13495704531669617, -0.1875881850719452, 0.04030044004321098, 0.009285283274948597]), layer_4 = (weight = [0.29861894249916077 -0.2665845453739166 … 0.25955483317375183 -0.12238256633281708; 0.228017657995224 0.047643180936574936 … 0.11392178386449814 -0.27174055576324463; … ; 0.06563947349786758 -0.1023372933268547 … 0.24972623586654663 0.2221684753894806; 0.024736633524298668 0.04983555153012276 … -0.16247469186782837 0.20062610507011414], bias = [-0.10133612155914307, 0.11978881061077118, 0.04166877269744873, 0.11940161883831024, -0.08117766678333282, -0.020776033401489258, 0.13517001271247864, 0.11456074565649033, -0.1255386620759964, 0.11233584582805634 … -0.10811863094568253, 0.07963871955871582, -0.1980079859495163, 0.021682213991880417, 0.08653130382299423, 0.021163558587431908, 0.185489222407341, 0.05204436928033829, -0.08581402152776718, 0.1616944819688797]), layer_5 = (weight = [-0.31101325154304504 0.10640417784452438 … -0.3169981837272644 0.17244073748588562], bias = [0.09212841838598251]))Step 6: Solve the Optimization Problem
callback = function (state, l)
println("Current loss is: $l")
return false
end
res = OPT.solve(prob, OptimizationOptimisers.Adam(0.01); callback = callback, maxiters = 2500);retcode: Default
u: ComponentArrays.ComponentVector{Float64, CUDA.CuArray{Float64, 1, CUDA.DeviceMemory}, Tuple{ComponentArrays.Axis{(layer_1 = ViewAxis(1:100, Axis(weight = ViewAxis(1:75, ShapedAxis((25, 3))), bias = ViewAxis(76:100, Shaped1DAxis((25,))))), layer_2 = ViewAxis(101:750, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_3 = ViewAxis(751:1400, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_4 = ViewAxis(1401:2050, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_5 = ViewAxis(2051:2076, Axis(weight = ViewAxis(1:25, ShapedAxis((1, 25))), bias = ViewAxis(26:26, Shaped1DAxis((1,))))))}}}(layer_1 = (weight = [4.856776911546949 4.4063789767175185 2.477125748317242; 3.8921432655344526 0.37502350294114345 0.43999404765336836; … ; 2.0421842989593375 0.8777319428286845 1.409386707846232; -1.1795880429916703 0.21746128483228194 -0.5853615522817507], bias = [-1.0560981578115527, -1.7675365346417486, -0.7285004538241416, 0.29940722422917115, 1.3400932986534602, 0.5222628246697153, 1.47935185939262, -1.737683620221056, 1.849427677314179, -0.759472706122743 … -0.3254016672615964, -0.7233588190384479, 0.050951228651131344, 2.9731874118211974, -0.19048011283425145, -0.5327712659598963, 2.024103409568719, 1.8260059527086632, -0.9089523067930223, 0.8182405915274088]), layer_2 = (weight = [0.5912133836022048 -1.138250770685181 … 0.5255027292984368 0.39822701918589554; -0.8126207195768819 0.9420718895559218 … -0.4180320853442257 0.9112653866836986; … ; 0.08391403227214643 1.2734569101704063 … -0.533951187720013 -0.7860049834089626; -0.3386046802198356 1.660481962098856 … -0.6161523698942153 -0.8850750343871783], bias = [0.028221707044782756, 0.17241733426358472, -0.03323763038231058, 0.056031730416644845, 0.15923667717714907, -0.3166985317642187, -0.13026018817288018, 0.014106823070039153, -0.03250197594885943, -0.2831003932700984 … -0.03710009798421813, 0.024009074674133313, -0.22157962980025123, 0.10508336065253282, 0.09089412869292475, -0.41787239655178116, 0.15460215098311786, -0.2643523843290373, -0.022245322972042802, 0.30087589311140095]), layer_3 = (weight = [-0.015894372546354577 0.41087076632744196 … -0.7605753467768585 -0.9825270333793436; 1.4070710620652724 0.3623628301707517 … -1.2903290605310351 -1.4711008224348257; … ; -0.40194624492833075 1.4949769190799702 … -0.2066709710214866 -0.5988340874152299; -0.153028209166267 1.0833985971797175 … -0.2948492008428817 -1.0674775359104043], bias = [-0.21574013990614785, -0.5539979595341697, -0.2956579811407785, 0.4061271639863495, -0.35282367743251575, -0.7178799415009797, -0.5394799697286704, -0.7687329751947546, -0.5871733171804954, -0.6884354350742954 … -0.7631730014588259, -0.5770517693095341, -0.35083373914467475, -0.7555353675909191, 0.5426438026810942, 0.050306272625699894, -0.21563081331031922, -1.0145485937502092, -0.3303871699237886, -0.32989437766442714]), layer_4 = (weight = [1.2215638518322984 1.0130597257994145 … 0.9543583958820054 0.858525466247479; -0.2934868464519938 -1.275794524081229 … -0.09500573935972896 -0.6965143312196479; … ; 2.383565448353845 2.3579488734392 … 2.5050407627524294 2.686205389824281; 0.5026331944518239 -0.9500266083128449 … -0.8810297481074737 0.20687314476811114], bias = [-1.1590348285488143, 1.1544953864262546, 0.9718262061372875, -0.8743224921515165, 0.9980542071220084, -1.4788148418463063, 1.0010913884126518, -1.1089436574640983, -0.9819732388526984, -1.002726901247173 … -1.2571331996985318, 1.6836626704155602, 0.6818099968741533, -1.8912188403407129, 1.1402529142159603, 1.2730160188361965, 1.7309162166494094, -1.1412079430028168, -1.626477077031537, 1.4525259402028334]), layer_5 = (weight = [-3.0387675961223337 5.884193530113195 … -3.2750483509537167 5.0352656451750315], bias = [1.0867877079822674]))We then use the remake function to rebuild the PDE problem to start a new optimization at the optimized parameters, and continue with a lower learning rate:
prob = OPT.remake(prob, u0 = res.u)
res = OPT.solve(prob, OptimizationOptimisers.Adam(0.001); callback = callback, maxiters = 2500);retcode: Default
u: ComponentArrays.ComponentVector{Float64, CUDA.CuArray{Float64, 1, CUDA.DeviceMemory}, Tuple{ComponentArrays.Axis{(layer_1 = ViewAxis(1:100, Axis(weight = ViewAxis(1:75, ShapedAxis((25, 3))), bias = ViewAxis(76:100, Shaped1DAxis((25,))))), layer_2 = ViewAxis(101:750, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_3 = ViewAxis(751:1400, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_4 = ViewAxis(1401:2050, Axis(weight = ViewAxis(1:625, ShapedAxis((25, 25))), bias = ViewAxis(626:650, Shaped1DAxis((25,))))), layer_5 = ViewAxis(2051:2076, Axis(weight = ViewAxis(1:25, ShapedAxis((1, 25))), bias = ViewAxis(26:26, Shaped1DAxis((1,))))))}}}(layer_1 = (weight = [6.6059265736657435 3.1627347717137155 2.2620131925739506; 3.86430837036296 0.3580730833484824 0.4826969373410933; … ; 2.393634541323331 1.1206590216821708 1.1955279103338894; -1.3659042836740796 0.032372295085826674 -0.41552269812603515], bias = [-1.1525598035398992, -1.8758748201708098, -0.7967677125505733, 0.035020751854729436, 1.343387863747272, 0.562954725216758, 1.5795837210518433, -1.8283668243610278, 1.8293229400987052, -0.8076532274382576 … -0.18817176946737563, -0.7022077871282195, 0.0037415308345679354, 3.449349877236915, -0.0874984208257208, -0.7139897453387891, 2.109234272713448, 1.7179660249660682, -0.7406561380094023, 0.9446456920517794]), layer_2 = (weight = [0.6569140538562822 -1.064219723700563 … 0.5904508973769654 0.3427693748613713; -0.9088249976327265 1.0705493432478281 … -0.352398871147804 0.7586477626203135; … ; 0.08267858046323216 1.2465163567869144 … -0.5601874384256914 -0.7355980422924874; -0.30083346462997224 1.7142560104847089 … -0.571157449691188 -0.7606219706884165], bias = [0.09379808352042761, 0.19672173967322912, 0.007555449414709045, 0.10433585711906912, 0.11017878719100146, -0.2516216363890391, -0.061468047555204956, 0.07559750946466066, 0.044366154071627584, -0.24312028474223576 … 0.03052160020606854, 0.07244778120415589, -0.2691622349775149, 0.1572439819888959, 0.17824034594301288, -0.5532601697423746, 0.10653519515217938, -0.3158971135451416, -0.056959766149284545, 0.3397822367230756]), layer_3 = (weight = [0.07617132508355745 0.5514960891158881 … -0.7177572309625881 -0.32258865972461626; 1.3604434920604296 0.735015895475055 … -0.930666809343459 -1.3535060057977952; … ; -0.4160206443174926 1.7460710038029446 … 0.07884771745130977 -0.24917525036412616; -0.06758515719677397 1.2614365562518226 … -0.08505759520768645 -0.9757298786823568], bias = [-0.3165870601428238, -0.32406091894416694, -0.31156061338015634, 0.4319572619885296, -0.21489320172875673, -0.759664882554301, -0.6598248528460454, -0.5794819910708064, -0.609660857460239, -1.4036656468323245 … -0.6101433626569024, -0.39571538160134695, -0.8643270254400602, -1.2473367826908213, 0.33680489618616555, 0.1846854919380985, -0.10727391528867404, -0.8158830890547805, -0.13270089624783027, -0.18617163351044588]), layer_4 = (weight = [1.354001490931744 1.3005856419458848 … 1.4712212445862407 1.192690143062701; -0.3321790834106463 -1.4024008361356335 … -0.3990857546856601 -0.8389510928067356; … ; 2.7993504625997314 2.9086212048920963 … 3.070854163445137 3.4499216703546502; 1.8214444721630987 -1.0423685766418613 … 0.5284829771411548 0.7900472893906729], bias = [-1.065438179837532, 0.9423085090883613, 0.8368451173143293, -0.7614568773494467, 0.7602227715996821, -1.4076240958978952, 0.8234838016574109, -1.2823632931677145, -0.8457620908951491, -0.7977667470943036 … -1.1182202563302215, 1.7024093029951473, 0.4532660009342148, -1.9594785185576902, 1.1906875636913643, 1.358033155308957, 1.2879265347236992, -0.9951613073858492, -1.691482245377484, 0.6598713115179399]), layer_5 = (weight = [-1.860559992787037 6.022261009261096 … -2.1370913033177263 7.724475594824931], bias = [2.302698257157607]))Step 7: Inspect the PINN's Solution
Finally, we inspect the solution:
phi = discretization.phi
ts, xs, ys = [infimum(d.domain):0.1:supremum(d.domain) for d in domains]
u_real = [analytic_sol_func(t, x, y) for t in ts for x in xs for y in ys]
u_predict = [first(Array(phi([t, x, y], res.u))) for t in ts for x in xs for y in ys]
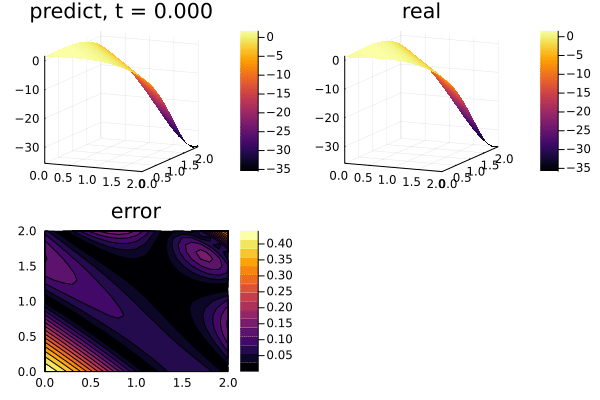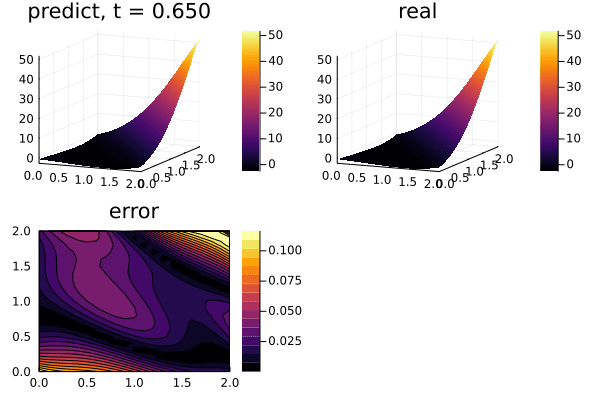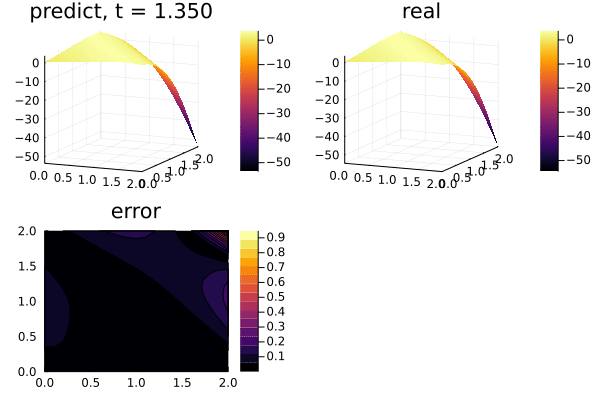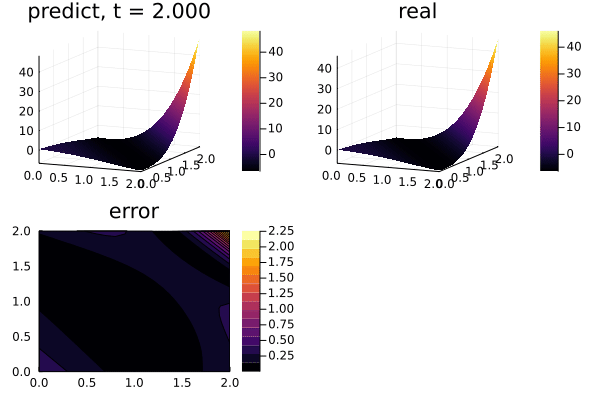
function plot_(res)
# Animate
anim = @animate for (i, t) in enumerate(0:0.05:t_max)
@info "Animating frame $i..."
u_real = reshape([analytic_sol_func(t, x, y) for x in xs for y in ys],
(length(xs), length(ys)))
u_predict = reshape([Array(phi([t, x, y], res.u))[1] for x in xs for y in ys],
length(xs), length(ys))
u_error = abs.(u_predict .- u_real)
title = @sprintf("predict, t = %.3f", t)
p1 = plot(xs, ys, u_predict, st = :surface, label = "", title = title)
title = @sprintf("real")
p2 = plot(xs, ys, u_real, st = :surface, label = "", title = title)
title = @sprintf("error")
p3 = plot(xs, ys, u_error, st = :contourf, label = "", title = title)
plot(p1, p2, p3)
end
gif(anim, "3pde.gif", fps = 10)
end
plot_(res)